Возможность дедупликации данных впервые появилась еще в Windows Server 2012. В Windows Server 2016 представлена уже третья версия компонента дедупликации, значительно переработанная и улучшенная. В этой статье мы поговорим о новых функциях дедупликации, ее настройках и отличиях от предыдущих реализаций.
Новые возможности дедупликации данных в Windows Server 2016
- Многопоточность. Первое и самое важное изменение в дедупликации данных в Windows Server 2016 — введение многопоточности. Дедупликация в Windows Server 2012 R2 работала только в однопоточном режиме и не могла использовать более одного процессорного ядра для одного тома. Это сильно ограничивало производительность, и для обхода этого ограничения необходимо было разбивать диски на несколько томов меньшего размера. Максимальный размер тома не должен превышать 10 Тб.
Обновленный движок дудупликации в Windows Server 2016 выполнять задания дедупликации в многопоточном режиме, причем каждый том использует несколько вычислительных потоков и очередей ввода-вывода. Введение многопоточности и других изменений в компоненте сказалось на ограничениях на размер файлов и томов. Поскольку многопоточная дедупликация повышает производительность и устраняет необходимость разбиения диска на несколько томов в Windows Server 2016, вы можете использовать дедупликацию для тома до 64 ТБ. Также увеличен максимальный размер файла, теперь поддерживается дедупликация файлов до 1 Тб. - Поддержка виртуализированных приложений резервного копирования. В Windows Server 2012 был только один тип дедупликации, предназначенный в основном для обычных файловых серверов. Дедупликация непрерывно работающей ВМ не поддерживается, поскольку дедупликации не знает, как работать с открытыми файлами.
Дедупликация в Windows Server 2012 R2 начала использовать VSS, соответственно, стала поддерживаться дедупликация виртуальных машин. Для таких задач использовался отдельный тип дедупликации.В Windows Server 2016 добавлен еще третий тип дедупликации, предназначенный специально для виртуализированных серверов резервного копирования (например, DPM). - Поддержка Nano Server. Nano Server – эта технология позволяет развертывать операционную систему Windows Server 2016 с минимальным количеством установленных компонентов. Nano Server полностью поддерживает дедупликацию.
- Поддержка последовательного обновления кластера (Cluster OS Rolling Upgrade). Cluster OS Rolling Upgrade – это новая функция Windows Server 2016, которая может использоваться для обновления операционной системы на каждом узле кластера с Windows Server 2012 R2 до Windows Server 2016 без остановки кластера. Это возможно благодаря специальной смешанной работе кластера, когда узлы кластера одновременно могут работать под управлением Windows Server 2012 R2 и Windows Server 2016.Смешанный режим означает, что одни и те же данные могут быть расположены на узлах с разными версиями компонента дедупликации. Дедупликация в Windows Server 2016 поддерживает этот режим и обеспечивает доступ к дедуплицированным данным в процессе обновления кластера.
- Многопоточность. Первое и самое важное изменение в дедупликации данных в Windows Server 2016 — введение многопоточности. Дедупликация в Windows Server 2012 R2 работала только в однопоточном режиме и не могла использовать более одного процессорного ядра для одного тома. Это сильно ограничивало производительность, и для обхода этого ограничения необходимо было разбивать диски на несколько томов меньшего размера. Максимальный размер тома не должен превышать 10 Тб.
Установка компонента дедупликации в Windows Server 2016
Первое, что нужно сделать, чтобы включить дедупликацию — это установить соответствующую роль сервера. Запустите Server Role wizard и добавьте роль файлового сервера с компонентом «Data Deduplication».
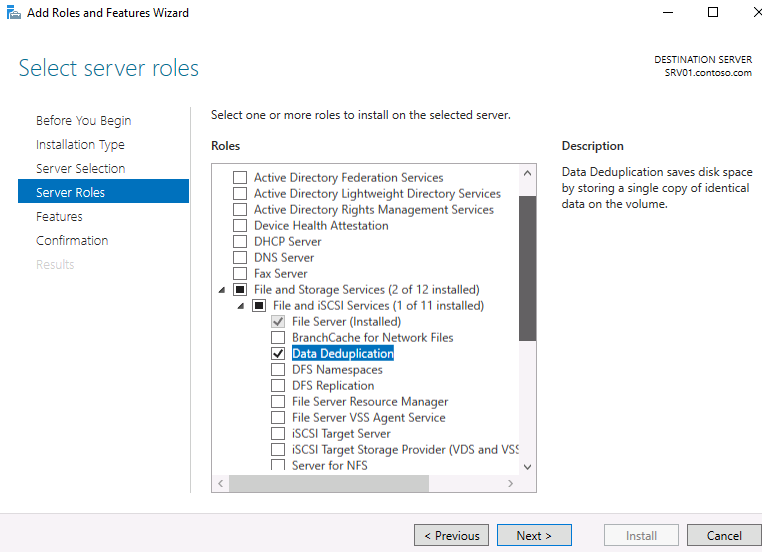
Или выполните следующую команду PowerShell:
Install-WindowsFeature -Name FS-Data-Deduplication -IncludeAllSubfeature -IncludeManagementTools

Включение и настройка дедупликации
После установки компонентов вам необходимо включить дедупликацию для определенного тома (или нескольких томов). Это можно сделать двумя способами: с помощью графического интерфейса или с помощью PowerShell.
Чтобы настроить компонент из GUI, откройте Server Manager, перейдите в File and storage services -> Volumes, выберите нужный том, щелкните правой кнопкой мыши и в меню выберите «Configure Data Deduplication».
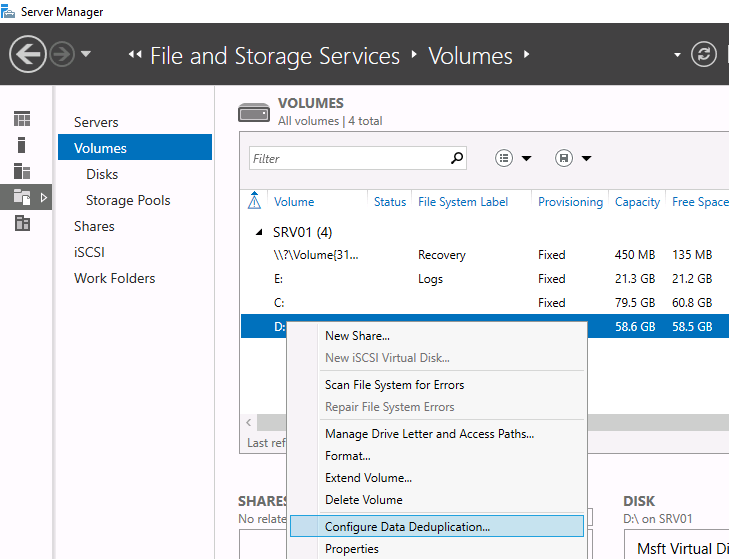
Затем выберите нужный тип дедупликации (например, General puprose file server) и нажмите «Применить». Кроме того, вы можете указать типы файлов, которые не должны подвергаться дедупликации, а также создать исключения для определенных каталогов (каталоги с мультимедиа файйлами, базами и т.д.).
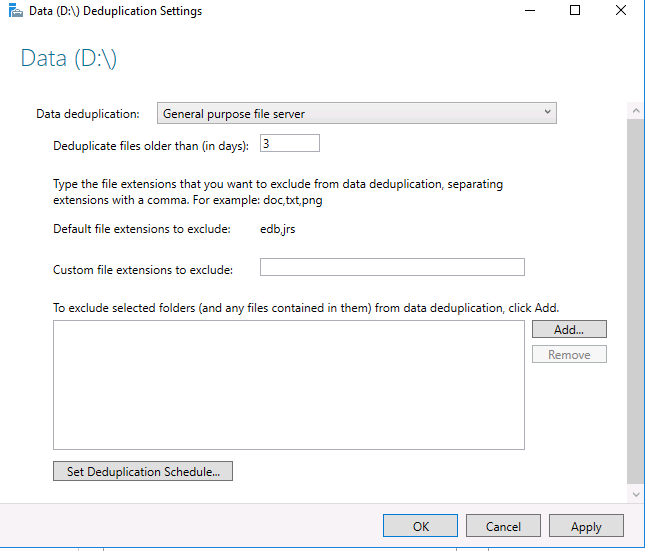
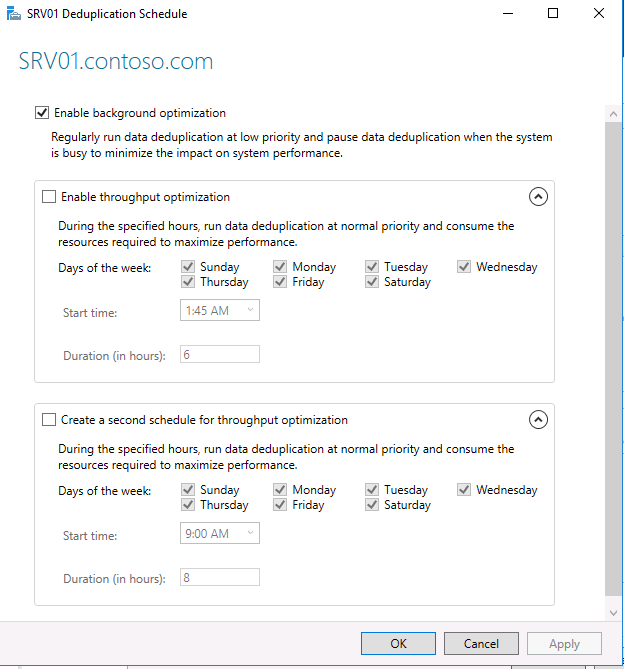
Затем вам необходимо настроить расписание, по которому будет работать задание дедупликации. Нажмите кнопку Set Deduplication Schedule.
По умолчанию включена фоновая оптимизация (background optimization), и вы можете настроить две дополнительные задачи принудительной оптимизации (throughput optimization). Здесь есть несколько настроек — вы можете выбрать дни недели, время начала и продолжительность работы.
Еще больше возможностей для настройки дедупликации предоставляет PowerShell. Чтобы включить дедупликацию, используйте следующую команду:
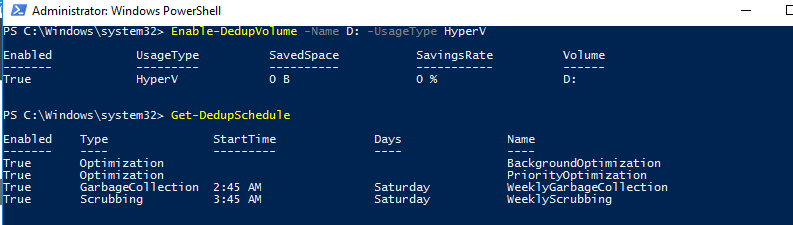
Enable-DedupVolume -Name D: -UsageType HyperV
Список текущих заданий дедупликации:
Get-DedupSchedule
Как вы видите, в дополнении к фоновой задачи оптимизации есть задача приоритетной оптимизации (PriorityOptimization), а также задания по сбору мусора (GarbageCollection) и очистке (Scrubbing). Все эти задачи нельзя увидеть в графическом интерфейсе.
PowerShell позволяет вам точно настроить параметры заданий дедупликации. Например, создадим такую задачу оптимизации: задача должна запускаться в 9 утра с понедельника по пятницу и работать 11 часов, с нормальным приоритетом, используя не более 20% ОЗУ и 20% CPU:
New-DedupSchedule -Name ThroughputOptimization -Type Optimization -Days @(1,2,3,4,5) -DurationHours 11 -Start (Get-Date ″20/05/2017 9:00 PM″) -Memory 20 -Cores 20 -Priority Normal
Отключим приоритетную оптимизацию:
Set-DedupSchedule -Name PriorityOptimization -Enabled $false
Ручной запуск дедупликации
При необходимости вы можете запустить задание дедупликации вручную. Например, запустим полную оптимизацию тома D: с наивысшим приоритетом:
Start-DedupJob -Volume D: -Type Optimization -Memory 75 -Cores 100 -Priority High -Full

Отслеживать выполнение заданий дедупликации можно с помощью команды Get-DedupJob. Заметим, что одновременно может выполняться только одна такая задача, остальные при этом находятся в очереди и ждут ее завершения.
Просмотр состояния дедупликации
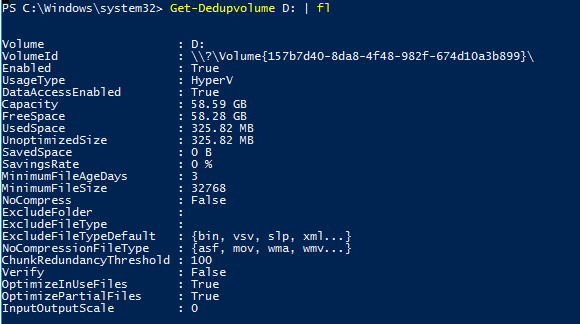
Состояние дедупликации данных для тома можно просмотреть, используя команду:
Get-DedupVolume -Volume D: | fl
Таким образом, вы можете видеть основные параметры тома — общий размер тома, использованный и сохраненный объем, уровень сжатия и т.д.
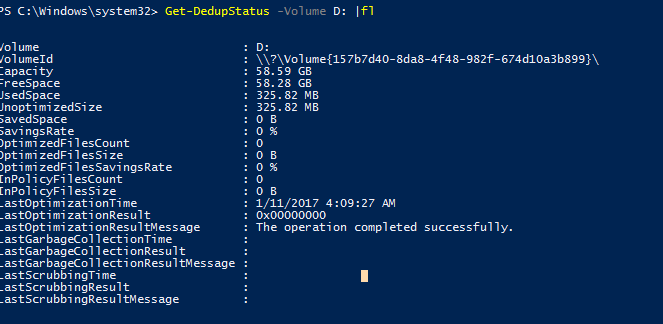
Чтобы проверить статус задания дедупликации, используйте команду:
Get-DedupStatus -Volume D: | fl
Как отключить дедупликацию
Вы можете отключить дедупликацию на диске из графического интерфейса или с помощью PowerShell. Например:
Disable-DedupVolume -Name D:

Отключение дедупликации для тома отменяет все запланированные задачи, а также предотвращает выполнение любых задач дедупликации, кроме операций на чтение (таких команд, как Get и unoptimization). Данные при этом остаются в неизменном состоянии, останавливается лишь дедупликация новых файлов.
Чтобы вернуть данные в исходное состояние, используйте процедуру обратной дедупликации. Например, выполните следующую команду для выполнения дедупликации данных на диске D с максимально возможной скоростью:
Start-DedupJob -Volume D: -Type Unoptimization -Memory 100 -Cores 100 -Priority High -Full

Обратите внимание, что для выполнения раздедупликации потребуется дополнительное пространство. Если свободного места на томе недостаточно, процедура не будет выполнена.